

图说:全球首个千卡规模异构芯片混训平台发布 采访对象供图(下同)
“打开水龙头前,我们不需要知道水是从哪条河里来的。同理,未来我们用各种ai应用时,也不会知道它调用了哪些基座模型,用到了哪种加速卡的算力——这就是最好的ai native 基础设施。”
4日,在2024年世界人工智能大会ai基础设施论坛上,无问芯穹联合创始人兼ceo夏立雪发布了全球首个千卡规模异构芯片混训平台,千卡异构混合训练集群算力利用率最高达到了97.6%。
同时,夏立雪介绍无问芯穹infini-ai云平台已集成大模型异构千卡混训能力,是全球首个可进行单任务千卡规模异构芯片混合训练的平台,具备万卡扩展性,支持包括amd、华为昇腾、天数智芯、沐曦、摩尔线程、nvidia六种异构芯片在内的大模型混合训练。7月起,通过试训申请的用户,已可在infini-ai上一键发起700亿参数规模的大模型训练。
打破异构芯片“生态竖井” 让异构芯片转化为大算力
作为大模型生命周期中不可或缺的两个阶段,训练和推理均需要强大的计算资源支撑。
然而,与国际上模型层与芯片层“相对集中”的格局相比,中国的模型层与芯片层更加“百花齐放”。然而,大量的异构芯片也形成了“生态竖井”,不同硬件生态系统封闭且互不兼容,给算力的使用方带来一系列技术挑战。
据不完全统计,宣布拥有千卡规模的中国算力集群已不少于100个,出于诸多缘由,比如过度依赖单一硬件平台可能会使企业面临供应链风险,又比如国产芯片的性能快速提升为集群方提供了多种选择,绝大部分集群已经或正在从同构转向异构。

“生态竖井”的存在让大多数企业和开发者对此望而却步,即便算力集群众多,也难以实现有效的整合与利用——这无疑是对算力资源的浪费。“生态竖井”不仅成为构建ai native基础设施的最大难点,也是当前大模型行业面临“算力荒”的重要原因。
构建适应多模型与多芯片格局的ai native基础设施,无问芯穹的底层解法是,提供高效整合异构算力资源的好用算力平台,以及支持软硬件联合优化与加速的中间件,让异构芯片真正转化为大算力。这一系列研、产进展背后,是无问芯穹研发团队在异构芯片计算优化与集群系统设计上的强大实力支撑。
日前,无问芯穹与清华、上交的联合研究团队发布了hethub,这是一个用于大规模模型的异构分布式混合训练系统,这是业内首次实现六种不同品牌芯片间的交叉混合训练,且工程化完成度高。夏立雪介绍,这项技术工程化的初衷,是希望能够通过整合更多异构算力,继续推高大模型技术能力的上限,同时通过打通异构芯片生态,持续降低大模型应用落地成本。

引领ai native基础设施建设 让天下没有难用的ai算力
当前,大模型行业发展正在进入规模化产业落地阶段,应用场景的百花齐放,带来了对大模型训练日益迫切的需求,巨大的市场前景,使得基础模型和算力芯片的行业玩家迅速攀升。构建大模型时代的ai native基础设施,不仅能够为ai开发者提供更加通用、高效、便捷的研发环境,同时也是实现算力资源有效整合,支撑ai产业可持续发展的关键基石。
无问芯穹具备顶尖的ai计算优化能力与算力九游会体育官网登录的解决方案能力,以及对“m种模型”与“n种芯片”行业格局的前瞻判断,率先构建了“mxn”中间层的生态格局,实现多种大模型算法在多元芯片上的高效、统一部署。
截至目前,infini-ai已支持了qwen2、glm4、llama3、gemma、yi、baichuan2、chatglm3系列等共30多个模型,以及amd、华为昇腾、壁仞、寒武纪、燧原、海光、天数智芯、沐曦、摩尔线程、nvidia等10余种计算卡。
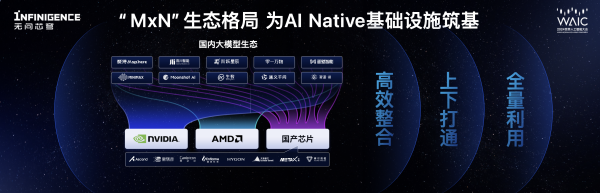
记者了解到,无问芯穹未来将继续突破异构算力优化与集群系统设计的技术上限,持续拓展模型层和芯片层的上下游生态伙伴力量,共同实现“mxn”的有效打通、利用和整合,构建真正适应多模型与多芯片的ai native基础设施,“让天下没有难用的ai算力”。
“技术上限推高与技术落地扩散不矛盾,且取决于我们决心如何对待这个技术。”夏立雪表示,今天说让大模型成本下降10000倍,就像30年前说让家家户户都通电一样。优良的基础设施就是这样一种“魔法”,当边际成本下降到临界值,就能有更多的人拥抱新技术。
新民晚报记者 郜阳